


#25 — La voix sous cloche


#26
Dans ce numéro :
→ Le long apprentissage de la recherche vocale
→ Une suprématie des GAFAM remise en cause ?
→ En bref
La première fois que j'ai entendu parler de Ray Kurzweil, fut en l'an 1999. A l'époque travaillant dans une agence de web design, on préparait nos clients à l'inévitable bug de l'an 2000 qui allait advenir. Moi-même je rédigeais les contenus d'un site web dédié au sujet. Comme toute designer de contenus, la recherche est un point capital... et à l'époque, si Google pointait le bout de son nez, nous utilisions encore Altavista. Eh donc, un jour, en faisant des recherches sur l'impact du bug de l'an 2000 pour le secteur de la santé (oui, oui, on ne rigole pas, c'était un sujet très sérieux à l'époque), je suis tombée sur le site de Ray Kurzweil. A l'époque, il ne se définissait pas encore comme transhumaniste, mais plutôt comme prospectiviste et futurologue. Sur son site, plusieurs articles parlaient néanmoins des bienfaits que l'intelligence artificielle apporterait au secteur médical...
Cependant, je délaissais rapidement la lecture de ces papiers auxquels je ne comprenais rien, par manque de culture sur le sujet, pour m'attarder sur une fonctionnalité qui m'interpellait en haut de page : un assistant vocal ou plutôt un assistant virtuel. En 1999, j'avais sous les yeux, le tout premier chat bot. Si, aujourd'hui, cette fonctionnalité s'est banalisée, elle était vraiment révolutionnaire à l'époque. Et je trouvais cette approche hyper intéressante pour ce qu'elle apportait à l'internaute, la possibilité de poser une question directement et d'avoir la réponse immédiatement. C'était plus pratique que d'aller chercher dans les FAQ souvent mal conçues des sites web.
J'étais bien sûr loin de me douter que ce chat bot préfigurait tout ce qu'il allait suivre par la suite. L'assistant virtuel de Ray Kurzweil n'était que le balbutiement de ce que Google a vite compris : les mots étaient une nouvelle frontière du capitalisme à conquérir. Aujourd'hui, les assistants vocaux ne sont que le énième avatar de ce capitalisme dont on ne connait pas encore les limites.
Bonne lecture !
-- Dominique

Photo de Mark Power, 2020
Le long apprentissage de la recherche vocale
La reconnaissance vocale a été inventée par Bell Labs en 1952. Sa technologie proposait de reconnaître une suite de 10 chiffres par un dispositif électronique câblé. Depuis lors, les évolutions technologiques se sont fortement accélérées, sous l’impulsion notamment du scientifique Fred Jelinek chez IBM de 1972 à 1993.
La longue marche vers l’initiation aux robots du langage naturel est pavée d’embûches. Google l’a appris à des dépens lorsqu’en 2007, il se lança sur avec Google Voice Search. Son périmètre d’action était alors réduit : il devait permettre aux internautes de dicter leur requête à la voix. Le search voice n’était alors qu’une oreille qui devait comprendre les mots prononcés par un utilisateur pour être traitée normalement par le moteur de recherche.
Google a rencontré plusieurs problèmes lors du développement de son outil. Apprendre le langage naturel à une IA est un long chemin compliqué.
L’une des premières difficultés concerne le bruit ambiant qui entoure une personne lorsqu’elle prononce à voix haute sa requête. Techniquement, c’est facile à faire mais le rendu est dégradé, baissant le taux de reconnaissance. Sur un smartphone, la probabilité d’un bruit ambiant étant forte, on mesure ici toute la complexité du problème.
Créer un système de langage naturel demande des ressources financières et humaines dont on ne mesure pas réellement l’ampleur. A savoir, la reconnaissance vocale doit être effective dans toutes les langues et lorsqu’une personne mélange des termes de plusieurs langues (exemple avec un Français qui intègre de l’anglais ou de l’italien dans ses énoncés vocaux), ça complexifie l’apprentissage.
De même, le défi repose aussi sur la prononciation. Il faut donc prendre en compte les différents types d’accent (l’accent du nord de la France est différent de l’accent marseillais) et les différences de timbre et d’intonations (mezzo, aigü, etc.).
Puis, la reconnaissance de la syntaxe est primordiale. Comme on l’a vu, chaque personne s’exprime différemment et il en est de même avec la connaissance syntaxique des utilisateurs.
Et enfin, la dernière difficulté consiste au traitement des données reçues simultanément par l’IA.
Depuis que Google s’est lancé dans l’aventure de la recherche vocale, il n’a jamais caché l’ambition de pousser l’expérience jusqu’à la recherche conversationnelle. Améliorer son moteur de recherche est l’obsession de la firme américaine et l’idée que l’utilisateur.ice puisse entamer une conversation avec le moteur de recherche est devenue le nerf de la guerre depuis quelques années.
Une suprématie des GAFAM remise en cause ?
Mais, on sait aujourd'hui, que tout ce que je viens d'écrire ci-dessus repose sur du vent. En effet, le bon fonctionnement des assistants vocaux repose aujourd'hui sur une multitude de petites mains humaines, touchant un salaire de misère, qui corrigent, ajustent quotidiennement les voix que ces enceintes enregistrent à notre insu. Je vous invite à regarder l'excellente série documentaire de France Télévisions, Invisibles ou à lire l'essai d'Antonio Casilli En attendant les robots : Enquête sur le travail du clic. Comme je l'écrivais dans le deuxième numéro de Futuromium, l'intelligence artificielle n'existe pas vraiment, c'est une invention sémantico-marketing.
En 2020, qu'en est-il vraiment ? Google n'est pas le seul acteur sur ce marché. Il doit supporter la concurrence des autres AFAM. Tous ont développé leur propre assistant vocal et tous disputent à Google son hégémonie du marché qu'il a lui-même préempté : le capitalisme linguistique. De Siri, qui équipe les iPhones et les Mac, aujourd'hui leader du marché à Amazon Echo, la bataille fait rage. Si aujourd'hui les GAFAM dominent le marché, il est probable que la donne change dans quelques années.
Si le vieux continent ne peut concurrencer, pour l'heur, les Américains, l'Asie et la Chine pourraient très bien jouer les troubles-fêtes. Il se posera alors pour l'Union Européenne, la sempiternelle question des enjeux éthiques et de comment créer des alternatives possibles. Les acteurs du marché européen avoue aujourd'hui qu'ils n'ont pas les moyens financiers pour supporter une R&D et préfèrent donc s'allier avec les forces déjà en présence, c'est le cas de Free et Orange qui ont choisi de travailler avec Amazon. On pensait pourtant qu'avec l'entreprise SNIPS, on s'acheminait vers une alternative véritablement française à une suprématie anglo-saxonne. Las, la pépite française a été rachetée par Sonos, une entreprise... américaine.
Alors sommes-nous voués à être toujours dépendant des mastodontes du secteur ? Et puis surtout avons-nous besoin de commander à voix haute toutes nos actions quotidiennes à une machine ? Je vous renvoie au numéro de la semaine dernière sur la maison connectée où j'y expliquais les problèmes éthiques.
Dans le graphe ci-dessous, extrait du livre blanc de la CNIL A votre écoute, vous y découvrirez les principaux usages des assistants vocaux. Pour 78% des personnes interrogées, la recherche d'informations sur la météo est la première requête, information qu'on a sur l'écran d'accueil de son smartphone, en écoutant la radio ou en regardant la TV... cette fonctionnalité est-elle nécessaire ? Non. Il en va de même pour tout le reste. Pour autant, nous avons adopté cette technologie sans nous poser la moindre question.
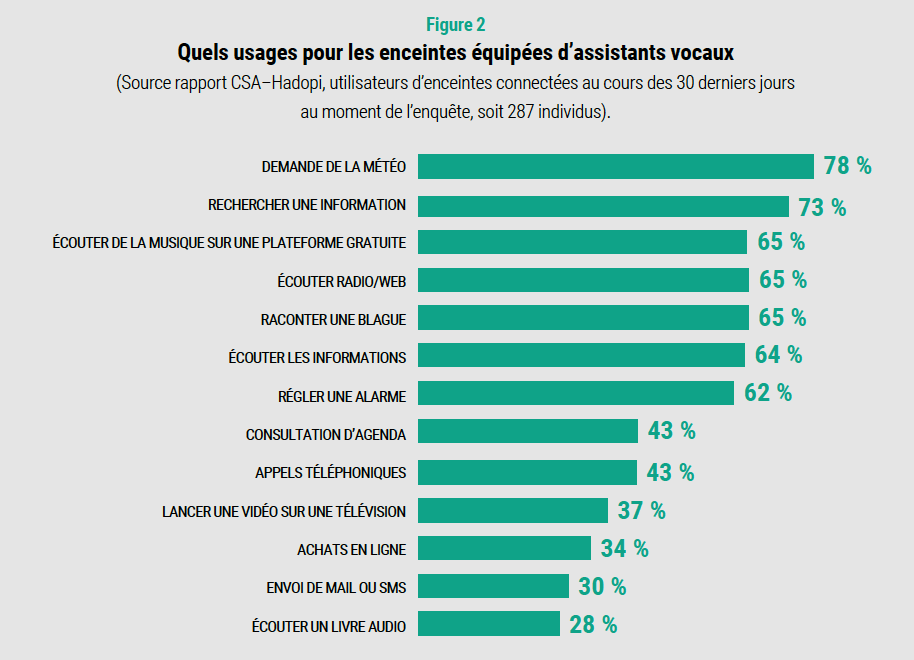
Se pose aussi la question de l'appropriation d'un savoir technique. Est-ce difficile de créer son propre assistant vocal ? En naviguant sur GitHub, vous découvrirez nombre de plateformes en open-source pour vous amuser à en faire un. Eh si vous souhaitez creuser le sujet, sachez qu'avec un raspberry pi couplé avec un arduino, vous pouvez construire votre propre Alexa ou Google Home. Vous réglez deux problèmes : votre vie privée est préservée des incidents de connexion, vous ne financez pas les GAFAM et cerise sur la voix, vous devenez un vrai maker.
En bref
→ Données personnelles : Bientôt un "cyberscore" pour afficher le niveau de protection des plateformes ?
→ Vie et mort du SNET, l'internet cubain
→ Portland, Maine hase voted to ban facial recognition